���e�F2008�N3��16��
���� 16: 2008�N7��27��
���ו��̍Œ��ɂ��܂��܁A2008-01-24 06:42 Re: �u�ӂ�ӂ���ۂ�ۂ�I�v����сA�u�ӂ�ӂ���ۂ�ۂ�I�v - �V�}�V�}�}�j�A�b�N�i�U�j / 2008-01-19 23:11��K�₵���ۂɁA�u�ӂ�ӂ���ۂ�ۂ�I�v�̃G���f�B���O�̋^��Ɋւ��ċ������������̂Œ��ׂĂ݂܂����B����������TV�����̎��_�ɂ��A���ׂ��͈͈ȊO�ł��̐�������ւ��ɂȂ��Ă���炵���Ǝv���A���������Ă��āu�悭�킩��Ȃ��Ȃ��c�v�Ɣ��R�Ǝv���Ă����̂ł��B
���u�ӂ�ӂ���ۂ�ۂ�I�v�Ƃ͌��삪���C�g�m�x���́u���D�����ܓ�m�{�����v��TV�A�j���Łi2007�N10���`�j�̃G���f�B���O�Ȃ̂��Ƃł��B����̐��D��l�i��e���ȁE���݂䂫�j�������I�Ɍ��݂ɉ̂��ӏ�������A���������������Ă��邽�߂ɂǂ��炪�̂��Ă���̂��������Ƃ����̂��A���������̋^��Ȃ킯�ł��B
�����̎����Ă���\�[�X�́ATV�f����MPEG-2�Ř^�悵�����WMV�i�������F48kbps, 44kHz, stereo�j�ɕϊ����Ă��܂����t�@�C������ēx�����o����WAV�����ł��邽�߁A���g���̏����12kHz���x�܂ŁA����MPEG��WMA�Ƃ��Ă̕s�t���k���o�Ă���_�ŁA�i���ɖ�肪���邱�Ƃ����f�肵�Ă����܂��B
�܂��A��͎��ɂ�WAV���g�p���܂������A�{�����y�[�W�Ōf�ڂ��Ă��鉹���t�@�C���́A�e�ʂ̓s���ōēxmp3�ɕϊ����Ă���܂��i�������o����WAV�t�@�C���ƍĕϊ�����mp3�t�@�C���̉�͌��ʂ̔�r�ł́A��藧�ĂĈႢ����������܂���ł����j�B
���̂��߃I���W�i���ɔ�ׂė��Ă���n�Y�ł����A�����̓�����10kHz���x�ӂ�܂łŌ�����n�Y�Ȃ̂ŁA�X���͓����ł��낤�Ǝv���܂��B
�����ۂɁA�u�₾�₾�v�������A�K���̃T���v��WAV�����Ǝ��̎���WMV�̉����ƂŔ�r����ƁA�g�`�ɈႢ������܂��B
���ꂾ���łȂ��A�������t�����̌��f�[�^�Ƃ����Ԃ����ĕ������܂��B�T���v�������̓t���o�[�W�����̂��̂炵���̂ł����ATV�Ƃ̓A�����W���قȂ��Ă���l�q�B
�Ƃ������A�m���ɂ悭�������Ȃ̂ŁA�꒮������x�ł́A
| No. | �t���[�Y | �P���C | ||||
|---|---|---|---|---|---|---|
| (1) | �u���������H�v | ���� Part1 | (2.24�b, MP3) | |||
| (2) | �u�{�C�H�v | ���� Part2 | (1.25�b, MP3) | |||
| (3) | �u�₾�₾�v | ���� Part3 | (0.93�b, MP3) | �₾�u��v�� | �����u��v | (0.40�b, MP3) |
| (4) | �u��������₾��v | ���� Part4 | (1.46�b, MP3) | ��������u��v���� | �����u��v | (0.38�b, MP3) |
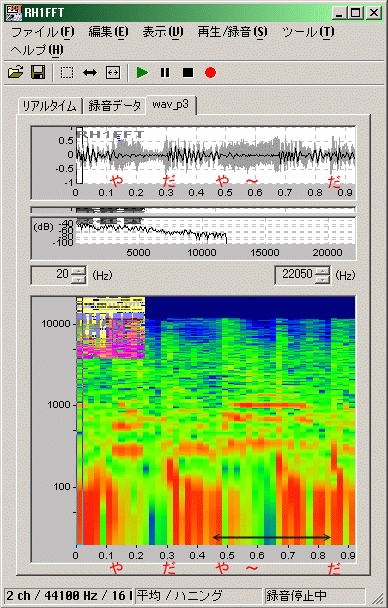
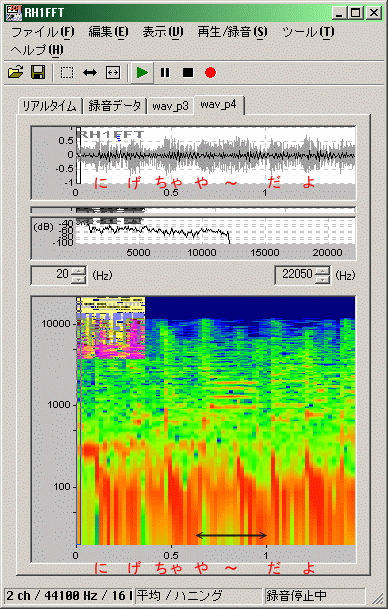
������₷���̂�(3)��(4)�Ɍ���鎗���������ш�́u�₾�v�́u��v�ŁA(4)�̂ق��������Ƀr�u���[�g���������������ɕ������܂��B�܂��A���������ʁA���������炩�ɓ����Ƃ͕������Ȃ��Ȃ�A�m���Ɍ��݂ɉ̂��Ă���Ɗ����܂��B
�u������v�����ł͋q�ϐ��ɖR�����̂ŁA�l�̐��̎��ʂɎg�����t�H���}���g�i�܂��͐���GVoice print; Spectrogram�j�̊ϓ_�Œ��ׂĂ݂܂����i�����郂�m�}�l�ł��t�H���}���g�ɂ͈Ⴂ���o��[*1]�Ƃ�����̂Łj�B
���������łȂ����t�����݂����f�[�^�Ȃ̂ŁA���̊��{������͂̎ז��ɂȂ錜�O�͑��X����܂��B�����̈�Əd�Ȃ�Ȃ����t�����͖������邾���ōς݂܂����A�̈悪�d�Ȃ鐬���͏������悤������܂���̂Łi���t�����̃t�@�C���ł�����������������̂ł������������f�[�^���Ȃ��Ȃ疳���j�B
(3)�u�₾��`���v�̌㔼�́u��`�v�ƁA(4)�́u����������`����v�́u��`�v�ɒ��ڂ���ƁA�Ƃ��Ɂu��v�̉��̏o�n�߁i�Z���ԁj�ƁA�������オ��㔼�i��ɕꉹ�́u���v�̌p�������j�Ƃɕ������܂��B
��������������i�L��/�_��/����/Web/blog�j��A������͂Ɏg�������ȃ\�t�g�E�F�A
�ȍ~�A�t�H���}���g�ɒ��ڂ��Ă݂܂��B
���Ȃ݂ɁA���͉����w���U�����킯�ł��Ȃ��A�S���̑f�l�ł��B�ߋ��ɒf�ГI�Ɍ������m���������ƁA����2�����x�̎�������Ȃǂœ����t���Đn�I�Ȓm�������ɂ��Ă��܂��̂ŁA���Ȃ�K���Ȃ��Ƃ������Ă���n�Y�ł��̂ŁA�L�ۂ݂ɂ��Ȃ��悤�ɂ��ĉ������B
�������A�G���̂Ȃ����{�ƂȂ������Ȃ��ɁA�G�����݁��i�����������ł̐l�����ꐫ���咣����̂́A�i�������Ƃ��鏤�������藧���Ă��邭�炢�ł����j���Ƃł�����悤�Ɍ�����̂ŁA���������ŏ����Ă��邱�Ƃ́A���Ȃ肢�������Ǝv���������ǂ��ł��傤�B
�A���A���ڂ̑命������v���Ȃ��Ă͓���ƌ���ł��Ȃ��̂ɑ��āA�����ł��Ⴄ�_��������u����łȂ��\��������v�Ƃ�����_�ɂ����āA�~���͑����Ⴂ�悤�Ɏv���܂��B
����A�O������������ƁA���ꂷ�����Ȃ邱�ƂɋC�t���܂����i�����̌��Ď������Q���j�B
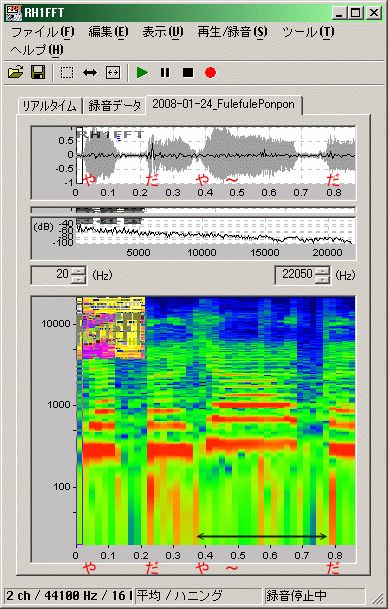
��͂ɗ��p�����̂�RH1FFT�̃\�m�O���t�i���X�y�N�g���O�����j�A�����Audacity�̔g�`�^�X�y�N�g���^�s�b�`�A����сAWaveSurfer�̔g�`�^�X�y�N�g���O�����^�i�s�b�`�j (Speech analysis; �s�b�`�͏���Ȃ������̂Ŋ���)�ASpectrogram 4.12�̃X�y�N�g���O�����ł��B
RH1FFT�̉�ʂ͍���̉�͂Ɏg��Ȃ��G���A���J�b�g���Ă���܂��BAudacity�AWaveSurfer�ASpectrogram 4.12�̐}�����l�ł��B
�Q�l�܂łɁA���{��̕ꉹ�u���v�̃t�H���}���g���g���́A��1�E2�t�H���}���g���A���ꂼ��780kHz�A1240kHz���x�ŁA��ʔF���ǂ���j����菗���̕����T�ˍ��߂̎��g���ƂȂ�܂��B�A���A�t�H���}���g���g�����邢�͐��䂾���Œj��������������ʂ���͖̂������Ƃ����L�q���������܂����B
����̌��f�[�^�ɂ́A�P�Ƃł͕ꉹ���܂܂�Ȃ��̂ŁA����Ɏq���́u��v�ɒ������܂��B�����������ꍇ�̌㔼�́u���v�ɋ߂������ɂȂ�ł��낤�Ƃ����u����v�Ɋ�Â��Ă��܂��i���A���̊J���������R�Ȃ���u���v�Ƃ͈قȂ�̂ŁA�����ɂ͂Ȃ�Ȃ��ł��낤�������m�ς݂ł��j�B
�������A�p�[�g(3)(4)�Ƃ��u��`�v�������x�̎��Ԕ�������Ă���_�ƁA�������C���u���v�ł��邱�ƂŁu���v�̔����̈ڍs�ω�������n�Y�ł���_�ɂ����āA���ɗp����u��`���v�͓s�����ǂ��Ƃ����܂��B
| �E(3)(4)���ꂼ��̃p�[�g�S�̕\������ׂ������@�i�N���b�N�Ő}�����\���j ���F�p�[�g(3)�A�E�F�p�[�g(4) |
|
|---|---|
 |
 |
| �E���ڂ����͈͂̎��ԕ����Ȃ�ׂ������ĕ��ׂ������@�i�N���b�N�Ő}�����\���j | |
 |
|
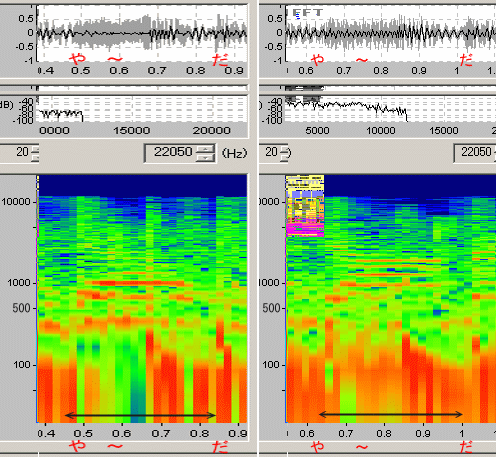
��RH1FFT�Œ��ڔ͈͂��������ԕ��ɂȂ�悤�Ƀp�[�g(4)���g��\�����Ă݂܂������A�����䗦�ɂł��Ȃ������̂ŁA2�Ԗڂ̐}�́A���̃p�[�g(3)���t�H�g���^�b�`�\�t�g�Ő}�`�I�ɉ������Ɋg�債�Ă���܂��B
�u��v�̏o�n�߂���0.03�b���x��800�`2kHz�O��̃s�[�N�����i�t�H���}���g�j������܂��i�u��v�Ɋ܂܂��ꉹ���u���v�Ȃ̂Łj�B�X��300�`400Hz�t�߂̃s�[�N���������m�ȈႢ�ƂȂ��Ă��܂��B���̐��������ɋN������̂�������܂���B���t�̐����ł��傤���H ����Ƃ��A�u��v�̔������Ɂu���v�̂悤�Ȕ��������邩��ł��傤���H�u���v�Ȃ��1�t�H���}���g��240�`300Hz������ł����c�B
�����t���x���̒Ⴂ�t���o�[�W�����̌��ʂ��l�����킹��ƁA300�`400Hz�t�߂����̐������Ǝv���܂����A���m�ɐ��̐����ƒf������̂�����Ȃ̂��m���ł��B
���l�@�F�u��v�̔������@�Ƃ��āu���v�Ɓu���v�������������Ŕ�������Ɓu��v�̂悤�Ȑ��ɂȂ�i�ꍇ�ɂ���Ă͖��ӎ��Ɂu����v�Ɣ�������ꍇ�����邩���j�B���̏ꍇ�u���v�̊���o��n�Y�B
���ɂ�����Βnj����Ă݂܂��B[Page.4]�ɂčl�@�B
�p�[�g(3)����300�`400Hz�t�߂������o�Ă��܂����p�[�g(4)�͎ア�ł��B�܂��p�[�g(3)�͖�1kHz�������o�Ă���̂ɑ��āA�p�[�g(4)��1kHz�����łȂ����̍����g���ɍׂ����s�[�N�����U���Ă��܂��B
�����ɂ͓����u��`�v�ł������̈Ⴂ������܂����A�����ŗp���������͓����̎����̂��������ł͂Ȃ����ߑO��̉e�����Ă���\��������܂����A����l���ł���ɑS�������ɂȂ��ł͂Ȃ��̂ŁA����1�̉��������Ř_����̂͊댯���Ƃ͎v���܂����A�u���v�ɋN�������1�E��2�t�H���}���g���g���̈Ⴂ���o�Ă���n�Y�Ȃ̂ŁA�����̈Ⴂ������������炵�Ă���̂ł͂Ȃ����Ǝv���܂��B
��100�`200Hz�O��ȉ��͔��t�̃r�[�g�����̉e���������Ǝv���邱�ƂƁA���̊�͂������������͈͂ł���ƍl�����邽�߁A��r�̑Ώۂ���O���Ă��܂��B�u���v�Ɋւ��Ă͑�1�t�H���}���g��200Hz�ɋ߂��̂Ŗ�������������܂��A�ȂɂԂ�G���������f�[�^�Ȃ̂ŁA��ނ܂���B
�ǂ��ł��傤���H
�����ĉ��߂ĉ������Ă݂�ƈ���ĕ������邩������܂���B
�t���o�[�W�����́A�`���ɏq�ׂ��ʂ艹������Ă��܂����A�p�[�g(3)�ɑ�������\�m�O���t�\���Ŏ��̌����������Ɠ��l��300�`400Hz�t�߂��Z���o�Ă��܂��B�����A���t�����Ƃ݂Ȃ��Ă��܂������A���t���T���߂ȉ��ʂł��邽�߂�0�`200Hz�t�߂̐������قƂ�Ǐo�Ă��Ȃ����ƁAPage.5�ł̍l�@3�APage.6�ł̍l�@4�̌�̍Ē����ŁA���t���x�����Ⴂ�ɂ�������炸�����Ɠ�������300�`400Hz�������o�Ă��邱�Ƃ���A����͐��̐����ł���Ɣ��f���C�����܂����B�A���ATV�ł͔��t�������傫���̂ŁA��̒��ӂ��K�v�ł��B1kHz�`2kHz�`�t�߂����̌��f�[�^�ƈ���āA�Z���o�Ă��܂����B�p�[�g(4)�ɑ������镔���ł��̂����肪�ǂ��Ȃ��Ă��邩�A�܂����o��Ő��̐k����̍����A��r���Ă݂�Ɖ����킩�邩������܂���B
��Page.2��WaveSurfer�̌���������Ɨ�R�Ƃ���̂ł����A�t���o�[�W�����i44.1kHz 16bit PCM�����t�����ʂ����Ȃ��j�ƁA�����p�ӂ����f�[�^�iWMV������o���������j���ׂ�ƁA���̃f�[�^�͂��Ȃ���Ă���A�����̓������s���ĂɂȂ��Ă��܂��Ă��܂��B���̂��߃t���o�[�W�����ł̃p�[�g(3)�ƃp�[�g(4)���ׂ�ƁA�Ⴂ�����������͂����肷�邩������܂���B
���y�[�W�ȍ~�ŁARH1FFT�ȊO�̉�̓\�t�g�E�F�A�ł̌��ʂ�^��_�̍l�@�ɂ��ċL�q���Ă��܂��B�ŏI���_�Ƃ��ẮA0.5�b�ɂ������Ȃ��f�[�^�ł̔��f�͋ɂ߂č���Ƃ������ƂɂȂ��Ă��܂��܂������A�{�҂ł̐��f�[�^�Ƃ���r�����݂��APage.2��WaveSurfer�ł̉���ł́A������������������Ƃ炦��ꂽ�Ƃ�����̂�������܂���B
��2008-04-30�Ƀt���o�[�W�����̌��ʂ�lj������Ƃ���A�u�������Ƃ炦��ꂽ�v�ƌ����͖̂���������Ɣ��f��ύX�B
���������F
����́A(1)1�̋Ȃ̒��ł́i�����炭���������Ƃ��āj�̂��ł��낤�Ƃ������ƁA(2)����^������ł�������Ă��Ȃ������O��ŋc�_���Ă��܂��B
(1)�Ɋւ��āF
���D���Ӑ}�I�ɕʂ̖��̐����������ꍇ�ɂ́A�ǂ���猋�\�t�H���}���g������Ă݂��܂��iPage.5���Q�Ƃ̂����j�B�u���m�}�l�ł��t�H���}���g�ɂ͈Ⴂ���o��v�Ƃ��u���F��ς��Ă����䂪���������番����v�Ƃ����̂��{���Ȃ̂��A�^��������n�߂Ă��܂��B
�Ⴆ�Ή����p�X���[�h���g���Z�L�����e�B�V�X�e���̎����ŁA�uB����A���̐���^���Ă��F�Œe�����v�u�̒��Ȃǂɂ��h�炬�ł��{�l�ƌ�������v�Ƃ�����������Ό������܂��B�������AA�����Ӑ}�I�ɓo�^�������p�X���[�h�Ƃ͑S���ʂ̐l�̐�����������A�F����Ȃ��̂ł͂Ȃ����Ƃ����C������̂ł��c�i��������͔F����Ȃ��j�B
(2)�Ɋւ��āF
�ŋ߂ł́i�Ƃ����Ă��A���Ȃ��Ƃ�5�N�ȏ�O�j�A�������O���ĉ̂����̎�ł����������̂��Ă���悤�ɒ������Ƃ��o���āA�i�̂̉���ȃA�C�h���̎�Ȃǂ�CD�ł́j���ۂɂ����������삪����Ă��܂��B���ɂ��̂悤�ȑ��삪����Ă����Ȃ�A�������ς���Ă��܂��܂��B
���C������c�[����FAntares Auto-Tune Evo