初稿:2008年3月16日
改訂 20: 2008年11月3日
本題の検証は少しも進展のないまま、余談や脱線ばかり増えていきますが…、Page.7までを記述した後に見かけた、音声解析などに関連するページで興味をもったものに関して記しておきます。その一部は、既にPage.1の「後日見つけた資料(記事/Web/blog/書籍)」欄にリストアップしてあります。
ニコニコ動画にて、「初音ミクの音声解析」という動画が公開されています。専門家ではないと言う断り書き付きですが、Praatを使用して調べた結果を動画にされているようです。
ちなみに、この動画を見つける1週間ほど前に、偶然にもそっくりなことが書かれているWebページ「フォルマントを見てみる」を見つけていたのですが、もしかしたらそのWebページの著者による動画なのかな?と思うのです。Webページ側の情報によればフランス在住の方らしく、研究のため(?)に初音ミクを購入してフランス語の発音などを試みられているようで[*1]、その一環として初音ミクの声が不自然だと言うことで調査されています。
その調査で記されている、ミクのフォルマント分布の図がほとんど同一、且つ1オクターブ上のフォルマントに言及している点が特徴的なので、同一作者なのではないかと推測したわけです。
[2008-10-09 追記] 上記を記した後日(2008年8月)、ご本人からメールを戴きました。私が推測したとおりフランス語レッスンのWebページと音声解析動画は同じ作者でした。X68000の頃から音声合成などの研究をされていたとのことで、やはり私なんかよりかなり音声に関する知識をお持ちのようです。メールで別の動画に関してもご連絡いただいたので追加しておきます。
作者が同一かどうかはどうでもいいことですが、先の動画で「生身の人」だとオクターブが違ってもフォルマントは同じと述べられています(「ふれふれっぽんぽん!」の検証ページを書くまでは、私もそう思い込んできました)。
でも、Page.5やPage.6などで、ネットラジオ(のWMA音声)を素材としているものの一応は「生身の人」の声で特性を調べてみて、発声時の気分・状態(例えば驚いた時)などによって、フォルマント周波数が違っていると言わざるを得ないと思うに至っては、初音ミクのオクターブ違いの声でフォルマントが違うことが不自然さの原因だと言われると、それも要因のひとつかもしれないけれど、それだけかなぁ?とも思うわけです。「生身の人」のフォルマントだって違ってますし…。尤も、私も専門家ではない(というより先の動画の作者/先のWeb著者よりも見識がない)ので、的外れなことを述べているのかも知れませんが。
※ 人の場合でもフォルマントは動くけれど、ある程度の範囲に収まるという趣旨のコメントと、(VOCALOIDを使ったことがないので確かなことは言えないとの断りつきで)、生身の人間にある揺らぎが不足していることが機械っぽさを感じさせるのではないかという趣旨のコメントを、甲南大学の北村准教授からいただきました。
※ [2008-07-27 追加] 自分で「お」を発音してみて特性を見てみました(一応オクターブごとに変えて発音したつもり)。図は左→右の順に高い声。WaveSurferが示すF1〜F4は、ほぼ同じ周波数ですし、そのあたりは大雑把に見れば同じ特性に見えますが、それ以上の周波数では違っています。実際、スペクトログラムの強度を見る限りは、例えば中央と右側とでは4kHz付近以上は違って見えます。(下図は75%に縮小表示;クリックで元のサイズ)
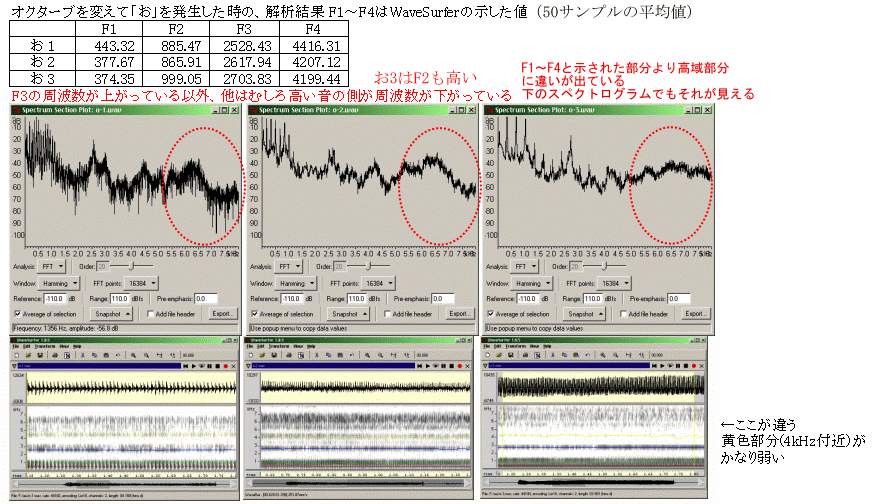
※ [2008-07-31 追加] フォルマントが平均的な日本語の母音から離れていると言うことに関しても、人の場合ですら個々人で母音の位置が違っている可能性がある例。
初音ミクの声は、声優の声をサンプルとして利用しているとはいえ、ヤマハの開発したVOCALOID2と呼ばれる音声合成エンジン&システムによる癖が出るので、生身の声とはならないのはもちろんですし、何らかの不自然さが出るのは尤もだと思います。実際に初音ミクを使った楽曲作品をいくつか聞いた感想でも、かなり素直に発声させていると思われるものでも(あるいは作者がそう述べている例[*2]でも)、機械音声っぽさは否定できません。それでも、ミク以前までの合成音声よりはずっと自然な歌声であるのも確かだとも思います。
[*2] 例えば、「MEW:初音ミク」の、「初音ミクのツボ<6> ミクらしさを大事にしよう」にて「素のミクがいちばんカワイイ」と書かれた結論をもとに作成された「涙にさよなら」や、(作者がどう述べているかは存じませんが)「おさななじみ」などは、比較的素直な発声だと思います。(ちなみに、「涙にさよなら」は、私が一番気に入っている初音ミクの曲です。livetune(=kz氏&かじゅき氏)、はやや〆氏、くちばし氏、その他の方々の作品も気に入っていますけど)
[*3] 初音ミクの声を提供した声優の藤田咲が、ミクのモノマネをしたという記事を見つけたのでリンクしておきます。音声も聞けます。元々本人の声をサンプリングしているだけあってよく似ています。逆にいえば、VOCALOID2を介しても酷く劣化していないともいえます。
ものはついでに、モノマネ部分の「ク」/「く」をチェックしてみました。初音ミクさんの声ではなく藤田咲さん本人の声の特性です。「初音ミクです」の「ク」と、「よろしく、ね」の「く」の音声ファイルとスペクトログラムです。音程と発声時間(および前後の語)が違う部分の特性です。そもそも音声波形からして違って見えています。さて、フォルマントの分布は同じに見えますか?違って見えますか?(私は違うと思うのですけどねぇ…) 図は、50%に縮小して表示しています(クリックで本来のサイズ)。
| 音声 | 「初音ミクです」の「ク」(音程高い) | 「よろしく、ね」の「く」(音程低い) |
|---|---|---|
| スペクトログラム | 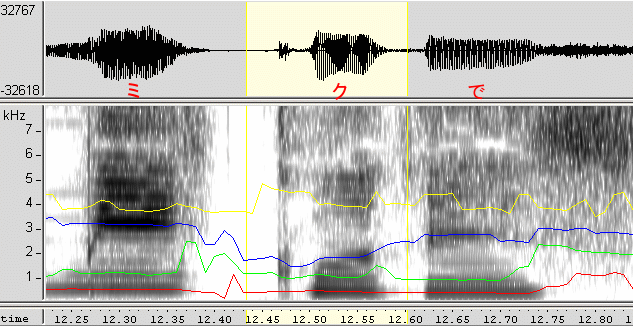 | 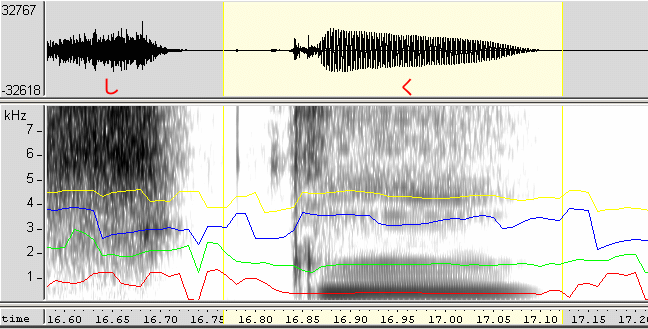 |
[*4] VOCALOID関連特許や、2007年8月のInterspeech2007で発表されたVOCALOIDに関する論文に関して言及しているblogと、論文。およびVOCALOID関連記事。
機械っぽさの理由に関しては置いておくとしても、初音ミクの音声特性に関しては(「ふれふれっぽんぽん!」の検証をしている最中にも)気になっていた事項だったので、面倒な作業をする手間が省けた上に(それ以前に私は初音ミクを購入していない!)、示された結果や考察はなかなか興味深く、参考になりました。
ちなみに、初音ミクの音声をスペクトログラム表示している別のWebページも見つけたのでリンクしておきます。
[*5] 5月頃に通称「ぼかりす」(=VocaListener)が登場していたのですね。これは「ユーザの歌唱音声から歌声合成パラメータを自動
推定するシステム」だそうです。2008年5月28日〜29日の音楽情報科学研究会 にて学会発表されたとの事。そのシステムに関する記述と別の類似手法などに関するWebページをリストアップしておきます。
サンプル音声を聞きましたが、自然なような不自然なような微妙な印象を受けました。基準とした歌唱の影響を受けているのかどうかなどは不明ですけど。似たようなことをしているらしいMikuMikuVoiceで作られた例や「ぼかんないんです><」の方が自然に感じたりしました。(例:【MikuMikuVoice】人間→ミク声変換でオリ曲を歌わせてみた【神ツール】‐ニコニコ動画/【本気MEIKO】 Dearest (pf mix) 【カバー曲】‐ニコニコ動画 | 【初音ミク】 Dearest (yks remix)+α 【カバー曲】)
[*6] 音のモーフィング(合成変異)をする技術 v.morishという研究も出てきました。
[*7] 歌唱ではなく話すことに重点を置いている例もあります。昔からAT&Tを含む電信系企業各社が取り組んでいる技術ですが、PENTAXの製品は結構自然かも。
音声や指紋その他いろいろな鑑定を扱う業者のページによれば、「特徴点合致法」によって同一性を判断するそうで、指標とされる値は「10秒間に12の特徴点」が揃えば、本人であると確認されるとのこと。また「良くある質問」のページによれば、録音物では劣化する旨、雑音がある場合は別途雑音のない音声が必要である旨、同じ言葉がない場合は「学術的な理論上では可能」だが「実務上は困難」である旨、男性の声か女性の声かの学術的検査方法が確立されていない旨などの記述が見つかります。Page.7までで判明していることと同じですね。
私が「ふれふれっぽんぽん!」の一連の検証で使用してきたRH1FFTは「試用」として利用してきました(そのためソノグラフ表示などにはっきりと見える通りRH1FFTのロゴが被っています(なぜか私のWindows Meではロゴ周りが四角く囲われて変なのですが、Windows 2000ではきちんとロゴだけが表示されます)。
つい先日、RH1FFTの作者が私のページをご覧下さり、私が「試用」状態で使っていることが原因で、いろいろと解析に制限が出ている様子なのでシェアウェア版を試してみてはどうでしょう?という、ご提案のメールを戴きました。正規版なら私が気にしていたソノグラフ(=スペクトログラム)表示の周波数範囲を絞ることができる上に、周波数解析時にオーバーラップ処理が可能になり、より詳しく解析ができるとのこと。
今はいろいろ忙しい上に(いつもの言い訳…)、根本的な部分で行き詰まっているので、正規版での解析が可能かどうか分かりませんが、暇を見てやってみるかも知れません。でも、元々調査したかったPage.1の音声に関しては、盛大にノイズが入っているなどの根本的な問題がなくならない限り、パラメータをいじれる版を使ったとしても解決できるメドがつきません。
RH1FFT作者のblogを拝見したところ、音声解析について、いろいろと言及されておられるようで、なかなか興味深いです。
センター入試の英語リスニングに使用されるプレイヤーの特性をチェックしているWebサイトを見つけたのでリンクしておきます。プレイヤーの再生能力がかなり劣っているようです。英語の聞き取りに使う装置なので、特性が悪いのは困りますね。どの程度の悪影響が在るのか、無視できる範囲なのかは不明ですが、音が割れてしまうなどの不具合は改良すべきでしょうね。コスト面で無理をしているのかもしれませんが、そのせいで正しい判定ができないとしたら受験者は不幸です。
また、言語学習関連のページで、スペクトログラムを示して発音が正しい/正しくないと書かれている例は結構見かけますが、英語の学習において音声分析が役に立つのかどうかと言うことについて言及されている例もリンクしておきます。