初稿:2008年3月16日
改訂 16: 2008年7月27日
考察3での声優が、比較的普通に話していると思われる音声を利用して特性を見てみました。利用したのは、茅原実里を含む3人がパーソナリティを務めるインターネットラジオ「みなみけのみなきけ 第18回」(WMAファイル)から抜き出したWAV音声(モノラル)です。「みなみけ」関連のラジオですが、多くの場面の声は千秋役とは異なり、普段の声と思われます。
使用した音声データは以下の通りです(3-1, 3-7など、一部に他の2人の声が重なっている場合があります)。
※解析時にはWAVを使用しましたが、本説明ページで掲載している音声ファイルは、容量の都合でmp3に変換してあります(※抜き出したWAVファイルと再変換したmp3ファイルの解析結果の比較では、取り立てて違いが見当たりませんでした)。
| No. | 単音韻 | フレーズ | ||||
|---|---|---|---|---|---|---|
| 「な」 | (3-1) | 「な」 | (0.20秒, MP3) | 「おじさんに変な…」 | (1.09秒, MP3) | |
| (3-2) | 「な」1番目 | (0.18秒, MP3) | 「頭が真っ白になり、 満員電車がトラウマになってしまいました」 | (3.36秒, MP3) | ||
| (3-3) | 「な」2番目 | (0.18秒, MP3) | ||||
| (3-4) | 「な」1番目 | (0.20秒, MP3) | 「痴漢に遭わないような、男の…」 | (1.95秒, MP3) | ||
| (3-5) | 「な」2番目 | (0.18秒, MP3) | ||||
| (3-6) | 「な」 | (0.18秒, MP3) | 「えぇ!こんなことってあるの?」 | (3.13秒, MP3) | ||
| (3-7) | 「な」 | (0.52秒, MP3) | 「そうだなぁ〜、でも…」 | (1.41秒, MP3) | ||
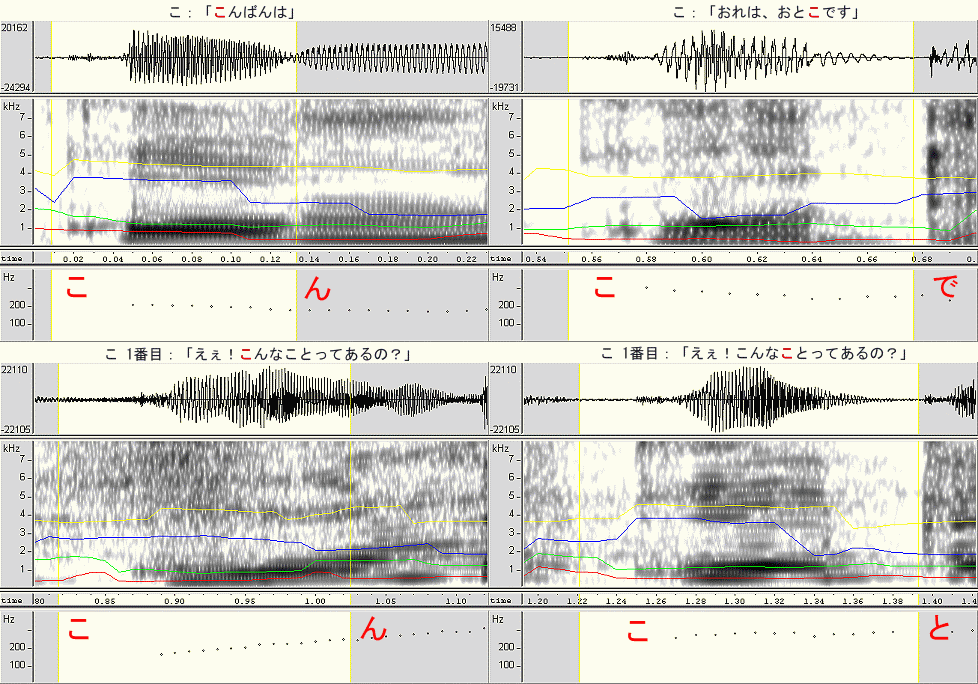
| 「こ」 | (4-1) | 「こ」 | (0.18秒, MP3) | 「こんばんは」 | (0.75秒, MP3) | |
| (4-2) | 「こ」 | (0.18秒, MP3) | 「俺は男です」 | (0.96秒, MP3) | ||
| (4-3) | 「こ」1番目 | (0.26秒, MP3) | 「えぇ!こんなことってあるの?」 | (3.13秒, MP3) | ||
| (4-4) | 「こ」2番目 | (0.20秒, MP3) | ||||
図を示します。今回はRH1FFT(波形/スペクトログラム)とWaveSurferを使います(波形/スペクトログラム/ピッチが表示されています)。いずれも縮小して表示しています。クリックで本来のサイズ(の75%)が見られます。
| 全体の特性 RH1FFT (時間幅は揃えてありません) |
|---|
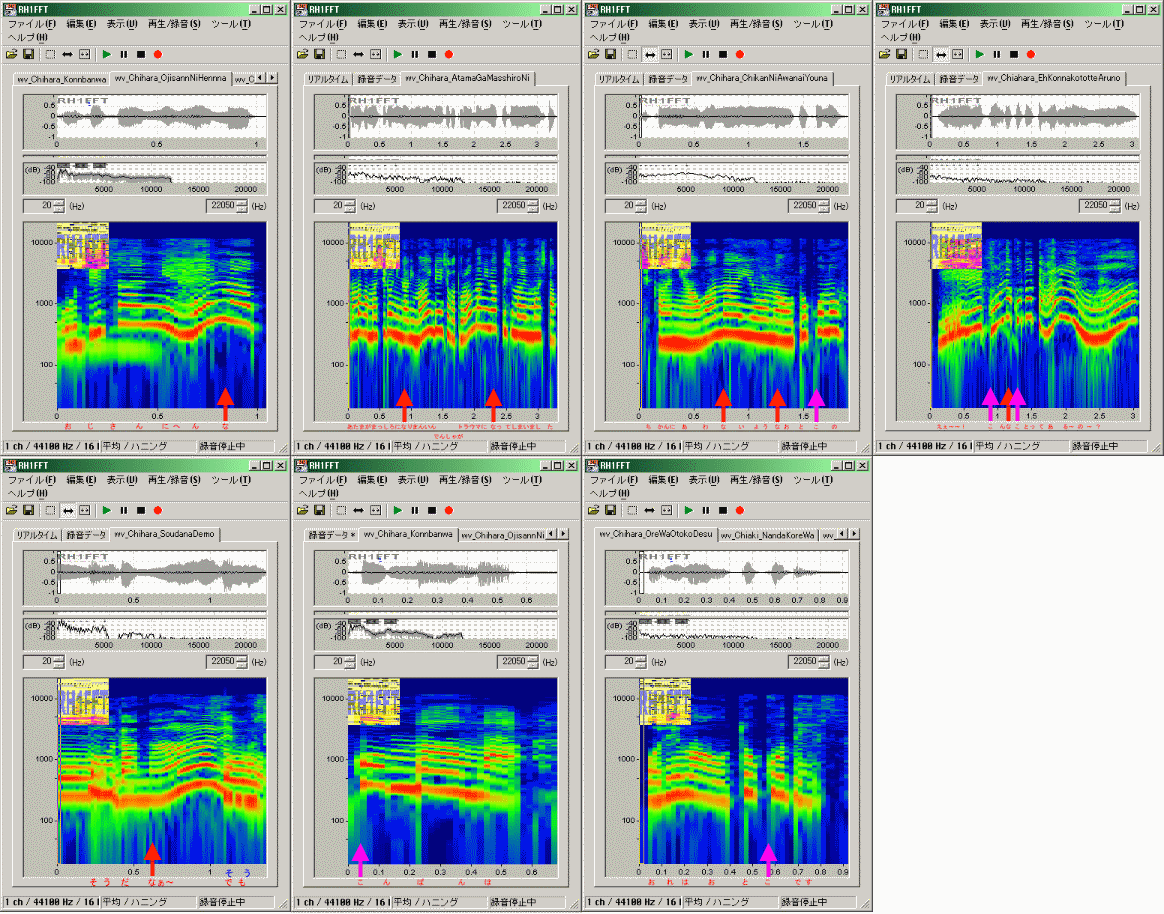 |
| 「な」の比較 RH1FFT (時間幅は揃えてありません) |
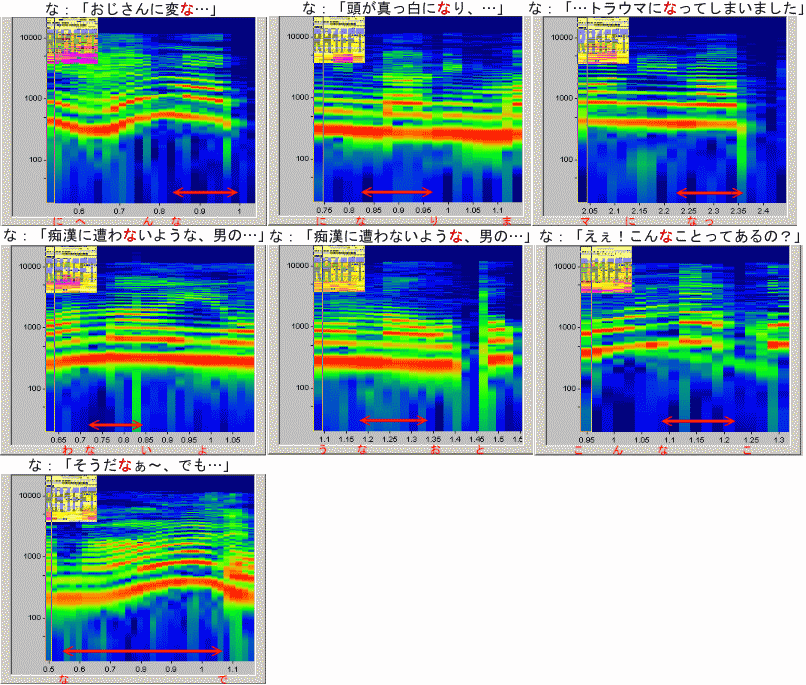 |
| 「な」の比較 (時間幅は揃えてありません;特に3-7) |
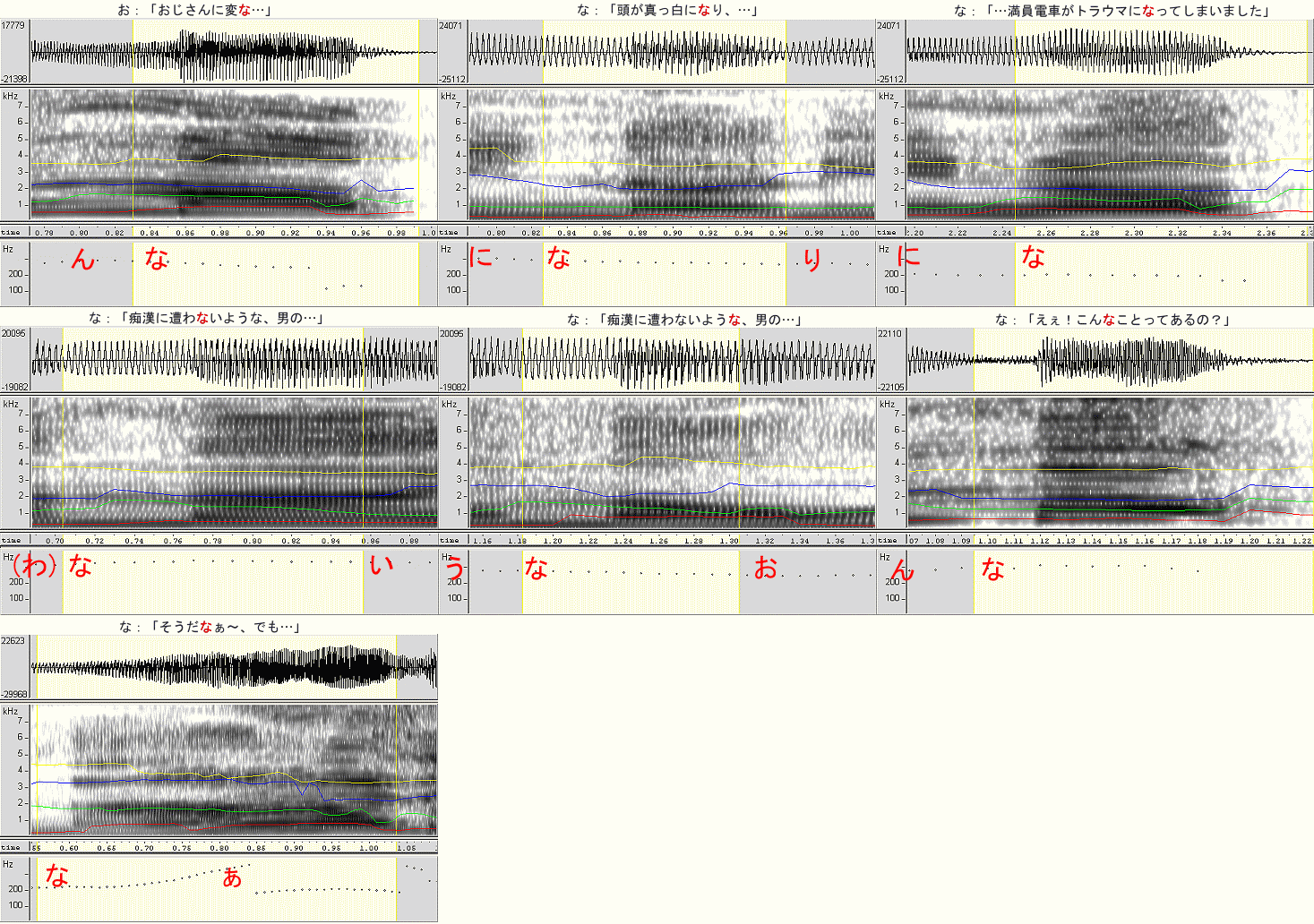 |
| 「こ」の比較 RH1FFT (時間幅は揃えてありません) |
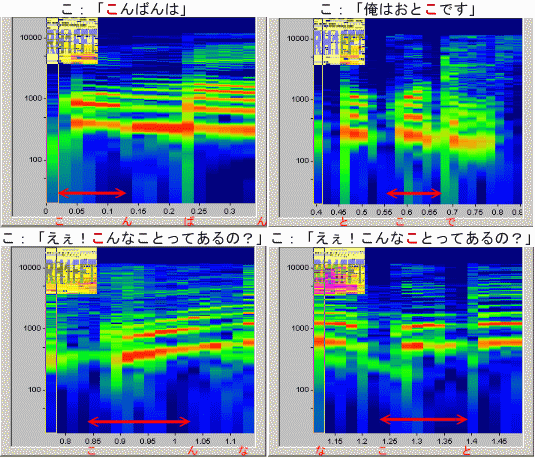 |
| 「こ」の比較 (時間幅は揃えてありません) |
 |
かなりばらつきますが、低めの声である3-2, 3-5, 3-7で千秋役の「な」に似た特性が出ています。3-1は低くないものの3kHz付近、6kHz付近の成分が抜け落ちている点でやや似ています。なお、RH1FFTの特性から分かるとおり、3-7は右肩上がりの発声がされており、WaveSurferでも途中から特性が変化してしまうのが見えますし、3-1では右肩下がりの発声のため、後半の成分が下がっていくのが見えます。それ以外は高めの声(驚いた声の3-6を含めて)のためか、スミレ役の「な」に似ているような似ていないような…という感じです。
4-2の「こ」は、やや低めの声で千秋役の「こ」に似ており、特性も良く似ています。4-1, 4-3, 4-4は高めの声(4-3, 4-4は驚いたときの声)であり、別の特性となっています。4-1と4-4では後者が高めに聞こえますが、特性は割と似て見えます。4-3では右上がりの抑揚のため、基音&倍音が右上がりに変化しているのが見えます。
今回、役作りから離れた声なら「素直」な普段の声の特性が見られるのではないかと考えて、割と自由に喋っているインターネットラジオの音声を利用しました。しかし、元々そうなのか、いろんな役を演じた結果ごちゃ混ぜになってしまっているのか不明ながら、投稿を読む際には割と明瞭且つ低めの千秋に似た感じ、フリートーク時にはやや舌っ足らずで高めのスミレに似た感じという具合に混在しており、声質に幅があることが分かります。また、音韻の発声が明瞭である場合と不明瞭である場合とで特性が変わってしまうことが分かりました。
また、200〜400Hzといったかなり低い周波数の成分も出ていることや、(当然といえば当然なことなのですが)同じ音韻でも抑揚(イントネーション)によって、その基音の周波数が変動することも分かりました。
Page.1〜3での調査における音声は、基音が伴奏でマスクされていたら、判定が難しくなる事が改めて判明しました。
※Page.4の考察1のデータでは200〜400Hz成分がほとんど見えてなかったことから、考察3・4の当初はRH1FFTでの調査を省略していました。しかし、同一性を疑うような結果の判断に困って、何気なくRH1FFTを加えてみたら、低い成分もかなりあることが分かり、考察3の音声も改めて調べてみたら同じく出ていることが判明した、といういきさつです。
(1)声質を変えられた場合、特性がずいぶん変わってしまうこと、(2)抑揚を変えて発声されたら、その都度、基音&その倍音が変化してしまうこと、(3)本来解析したかったPage.1に示した歌声のように、伴奏が盛大に混入しているデータでは200〜400Hz成分を見分けることが困難になるということ、などから同一性の確認は非常に難しいことが分かりました。考察3・4のデータのように、雑音が少なくてもかなり違って見えてしまうのに、これで本当に同一性などが判定できるのだろうか?という疑念が更に強まってしまいました。
もしも意図して違った声を出したなら、それが発声の仕方による違いなのか、人物の違いなのか、私にはもう判定できないというのが素直な感想です。
何か手がかりがつかめるかと思って複数のデータで考察してきたのですが、ほとんどお手上げという状態です。
ここまでの考察で決定打が得られなかったことの言い訳をするならば、音声パスワードシステムの例では、単音や短すぎるフレーズはダメで、数秒のフレーズを登録させなくてはいけない点がカギであろうということ。実際に、音声研究の第一人者(甲南大学理工学部 北村達也准教授;Page.1に示したPDF資料や「解体新ショー」)でも長いフレーズの抑揚(基本周波数の時間推移)に着目しています。つまり、特定のフレーズを話す際の抑揚の違いも判断材料にしており、今回の様に違うフレーズや0.5秒にも満たないデータでの判断はプロでも難しいであろう事が推測される点です。
但し、今回のPage.1〜3での音声に関しては、本編の音声との比較も追加したPage.2のWaveSurferで見られる特性「や」の出始めと収束性の観点で、もしかしたら違いを見出せたといえるのかもしれません。
※2008-04-30にフルバージョンの結果を追加したところ、特徴をとらえられたと言うのは無理があると判断を変更。
「プロでも難しいであろう」などと幾度も書いているので、では実際に専門家がどう判断するか聞いてみよう、というわけで、お尋ねした結果を次ページに記載しました。